Pybrain is an open-source library for Machine learning implemented using python. The library offers you some easy to use training algorithms for networks, datasets, trainers to train and test the network.
Definition of Pybrain as put by its official documentation is as follows −
PyBrain is a modular Machine Learning Library for Python. Its goal is to offer flexible, easy-to-use yet still powerful algorithms for Machine Learning Tasks and a variety of predefined environments to test and compare your algorithms.
PyBrain is short for Python-Based Reinforcement Learning, Artificial Intelligence, and Neural Network Library. In fact, we came up with the name first and later reverse-engineered this quite descriptive “Backronym”.
Features of Pybrain
The following are the features of Pybrain −
Networks
A network is composed of modules and they are connected using connections. Pybrain supports neural networks like Feed-Forward Network, Recurrent Network, etc.
feed-forward network is a neural network, where the information between nodes moves in the forward direction and will never travel backward. Feed Forward network is the first and the simplest one among the networks available in the artificial neural network.
The information is passed from the input nodes, next to the hidden nodes and later to the output node.
Recurrent Networks are similar to Feed Forward Network; the only difference is that it has to remember the data at each step. The history of each step has to be saved.
Datasets
Datasets is the data to be given to test, validate and train on networks. The type of dataset to be used depends on the tasks that we are going to do with Machine Learning. The most commonly used datasets that Pybrain supports are SupervisedDataSet and ClassificationDataSet.
SupervisedDataSet − It consists of fields of input and target. It is the simplest form of a dataset and mainly used for supervised learning tasks.
ClassificationDataSet − It is mainly used to deal with classification problems. It takes in input, target field and also an extra field called “class” which is an automated backup of the targets given. For example, the output will be either 1 or 0 or the output will be grouped together with values based on input given, i.e., either it will fall in one particular class.
Trainer
When we create a network, i.e., neural network, it will get trained based on the training data given to it. Now whether the network is trained properly or not will depend on the prediction of test data tested on that network. The most important concept in Pybrain Training is the use of BackpropTrainer and TrainUntilConvergence.
BackpropTrainer − It is a trainer that trains the parameters of a module according to a supervised or ClassificationDataSet dataset (potentially sequential) by backpropagating the errors (through time).
TrainUntilConvergence −It is used to train the module on the dataset until it converges.
Tools
Pybrain offers tools modules which can help to build a network by importing package: pybrain.tools.shortcuts.buildNetwork
Visualization
The testing data cannot be visualized using pybrain. But Pybrain can work with other frameworks like Mathplotlib, pyplot to visualize the data.
Advantages of Pybrain
The advantages of Pybrain are −
-
Pybrain is an open-source free library to learn Machine Learning. It is a good start for any newcomer interested in Machine Learning.
-
Pybrain uses python to implement it and that makes it fast in development in comparison to languages like Java/C++.
-
Pybrain works easily with other libraries of python to visualize data.
-
Pybrain offers support for popular networks like Feed-Forward Network, Recurrent Networks, Neural Networks, etc.
-
Working with .csv to load datasets is very easy in Pybrain. It also allows using datasets from another library.
-
Training and testing of data are easy using Pybrain trainers.
Limitations of Pybrain
Pybrain offers less help for any issues faced. There are some queries unanswered on stackoverflow and on Google Group.
Workflow of Pybrain
As per Pybrain documentation the flow of machine learning is shown in the following figure −
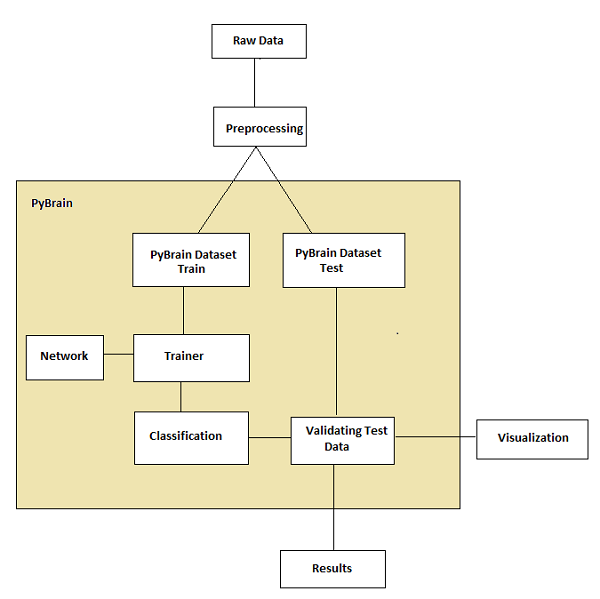
At the start, we have raw data which after preprocessing can be used with Pybrain.
The flow of Pybrain starts with datasets which are divided into trained and test data.
-
the network is created, and the dataset and the network are given to the trainer.
-
the trainer trains the data on the network and classifies the outputs as trained error and validation error which can be visualized.
-
the tested data can be validated to see if the output matches the trained data.
Terminology
There are important terms to be considered while working with Pybrain for machine learning. They are as follows −
Total Error − It refers to the error shown after the network is trained. If the error keeps changing on every iteration, it means it still needs time to settle, until it starts showing a constant error between iteration. Once it starts showing the constant error numbers, it means that the network has converged and will remain the same irrespective of any additional training is applied.
Trained data − It is the data used to train the Pybrain network.
Testing data − It is the data used to test the trained Pybrain network.
Trainer − When we create a network, i.e., neural network, it will get trained based on the training data given to it. Now whether the network is trained properly or not will depend on the prediction of test data tested on that network. The most important concept in Pybrain Training is the use of BackpropTrainer and TrainUntilConvergence.
BackpropTrainer − It is a trainer that trains the parameters of a module according to a supervised or ClassificationDataSet dataset (potentially sequential) by backpropagating the errors (through time).
TrainUntilConvergence − It is used to train the module on the dataset until it converges.
Layers − Layers are basically a set of functions that are used on hidden layers of a network.
Connections − A connection works similar to a layer; an only difference is that it shifts the data from one node to the other in a network.
Modules − Modules are networks which consists of input and output buffer.
Supervised Learning − In this case, we have an input and output, and we can make use of an algorithm to map the input with the output. The algorithm is made to learn on the training data given and iterated on it and the process of iteration stops when the algorithm predicts the correct data.
Unsupervised − In this case, we have input but don”t know the output. The role of unsupervised learning is to get trained as much as possible with the data given.