It is basically the extension of simple linear regression that predicts a response using two or more features. Mathematically we can explain it as follows −
Consider a dataset having n observations, p features i.e. independent variables and y as
one response i.e. dependent variable the regression line for p features can be calculated as follows −
$$hleft ( x_{i} right )=b_{0}+b_{1}x_{i1}+b_{2}x_{i2}+cdot cdot cdot +b_{p}x_{ip}$$
Here,$hleft ( x_{i} right )$ is the predicted response value and $b_{0},b_{1},b_{2}….b_{p}$ are the regression coefficients.
Multiple Linear Regression models always includes the errors in the data known as residual error which changes the calculation as follows −
$$hleft ( x_{i} right )=b_{0}+b_{1}x_{i1}+b_{2}x_{i2}+cdot cdot cdot +b_{p}x_{ip}+e_{i}$$
We can also write the above equation as follows −
$$y_{i}=hleft ( x_{i} right )+e_{i}:: or :: e_{i}=y_{i}-hleft ( x_{i} right )$$
Python Implementation
To implement multiple linear regression in Python using Scikit-Learn, we can use the same LinearRegression class as in simple linear regression, but this time we need to provide multiple independent variables as input.
Let”s consider the Boston Housing dataset from Scikit-Learn and implement multiple linear regression using it.
Example
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import numpy as np
import matplotlib.pyplot as plt
# Load the Boston Housing dataset
boston = load_boston()
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(boston.data,
boston.target, test_size=0.2, random_state=0)
# Create a linear regression object
lr_model = LinearRegression()
# Fit the model on the training data
lr_model.fit(X_train, y_train)
# Make predictions on the test data
y_pred = lr_model.predict(X_test)
# Calculate the mean squared error
mse = mean_squared_error(y_test, y_pred)
# Calculate the coefficient of determination
r2 = r2_score(y_test, y_pred)
print(''Mean Squared Error:'', mse)
print(''Coefficient of Determination:'', r2)
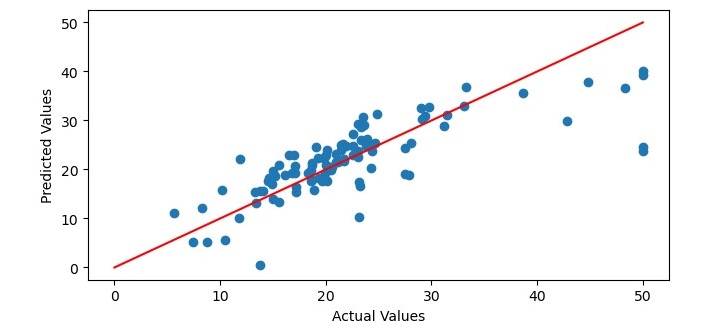
# Plot the predicted values against the actual values
plt.figure(figsize=(7.5, 3.5))
plt.scatter(y_test, y_pred)
plt.xlabel(''Actual Values'')
plt.ylabel(''Predicted Values'')
# Add a regression line to the plot
x = np.linspace(0, 50, 100)
y = x
plt.plot(x, y, color=''red'')
# Show the plot
plt.show()
In this code, we first load the Boston Housing dataset using the load_boston() function from Scikit-Learn. We then split the dataset into training and testing sets using the train_test_split() function.
Next, we create a LinearRegression object and fit it on the training data using the fit() method. We then make predictions on the test data using the predict() method and calculate the mean squared error and coefficient of determination using the mean_squared_error() and r2_score() functions, respectively.
Finally, we plot the predicted values against the actual values using the scatter() function and add a regression line to the plot using the plot() function. We label the x-axis and y-axis using the xlabel() and ylabel() functions and display the plot using the show() function.
Output
When you execute the program, it will produce the following plot as the output and it will print the Mean Squared Error and the Coefficient of Determination on the terminal −
Mean Squared Error: 33.44897999767653 Coefficient of Determination: 0.5892223849182507