The K-Means algorithm can be summarized into the following steps −
-
Initialization − Select K random data points as the initial centroids.
-
Assignment − Assign each data point to the closest centroid.
-
Recalculation − Recalculate the centroids by taking the mean of all data points in each cluster.
-
Repeat − Repeat steps 2-3 until the centroids no longer move or the maximum number of iterations is reached.
The K-Means algorithm is a straightforward and efficient algorithm, and it can handle large datasets. However, it has some limitations, such as its sensitivity to the initial centroids, its tendency to converge to local optima, and its assumption of equal variance for all clusters.
Implementation in Python
Python has several libraries that provide implementations of various machine learning algorithms, including K-Means clustering. Let”s see how to implement the K-Means algorithm in Python using the scikit-learn library.
Step 1 − Import Required Libraries
To implement the K-Means algorithm in Python, we first need to import the required libraries. We will use the numpy and matplotlib libraries for data processing and visualization, respectively, and the scikit-learn library for the K-Means algorithm.
import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans
Step 2 − Generate Data
To test the K-Means algorithm, we need to generate some sample data. In this example, we will generate 300 random data points with two features. We will visualize the data also.
X = np.random.rand(300,2) plt.figure(figsize=(7.5, 3.5)) plt.scatter(X[:, 0], X[:, 1], s=20, cmap=''summer''); plt.show()
Step 3 − Initialize K-Means
Next, we need to initialize the K-Means algorithm by specifying the number of clusters (K) and the maximum number of iterations.
kmeans = KMeans(n_clusters=3, max_iter=100)
Step 4 − Train the Model
After initializing the K-Means algorithm, we can train the model by fitting the data to the algorithm.
kmeans.fit(X)
Step 5 − Visualize the Clusters
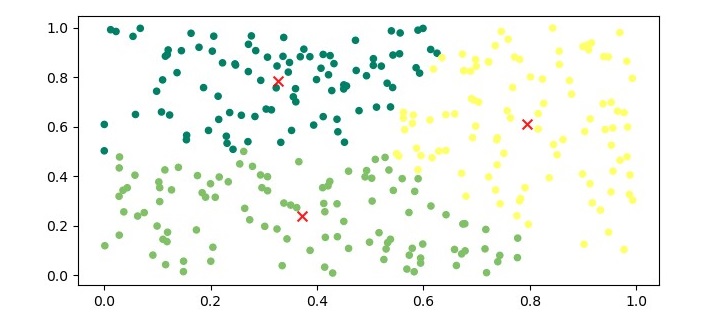
To visualize the clusters, we can plot the data points and color them based on their assigned cluster.
plt.figure(figsize=(7.5, 3.5)) plt.scatter(X[:,0], X[:,1], c=kmeans.labels_, s=20, cmap=''summer'') plt.scatter(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1], marker=''x'', c=''r'', s=50, alpha=0.9) plt.show()
The output of the above code will be a plot with the data points colored based on their assigned cluster, and the centroids marked with an ”x” symbol in red color.
Complete Implementation Example
Here is the complete implementation example of K-Means Clustering Algorithm in python −
import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans X = np.random.rand(300,2) plt.figure(figsize=(7.5, 3.5)) plt.scatter(X[:, 0], X[:, 1], s=20, cmap=''summer''); plt.show() kmeans = KMeans(n_clusters=3, max_iter=100) kmeans.fit(X) plt.figure(figsize=(7.5, 3.5)) plt.scatter(X[:,0], X[:,1], c=kmeans.labels_, s=20, cmap=''summer'') plt.scatter(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1], marker=''x'', c=''r'', s=50, alpha=0.9) plt.show()
Output
When you execute this code, it will produce the following plots as the output −
Applications of K-Means Clustering
K-Means clustering is a versatile algorithm with various applications in several fields. Here we have highlighted some of the important applications −
Image Segmentation
K-Means clustering can be used to segment an image into different regions based on the color or texture of the pixels. This technique is widely used in computer vision applications, such as object recognition, image retrieval, and medical imaging.
Customer Segmentation
K-Means clustering can be used to segment customers into different groups based on their purchasing behavior or demographic characteristics. This technique is widely used in marketing applications, such as customer retention, loyalty programs, and targeted advertising.
Anomaly Detection
K-Means clustering can be used to detect anomalies in a dataset by identifying data points that do not belong to any cluster. This technique is widely used in fraud detection, network intrusion detection, and predictive maintenance.
Genomic Data Analysis
K-Means clustering can be used to analyze gene expression data to identify different groups of genes that are co-regulated or co-expressed. This technique is widely used in bioinformatics applications, such as drug discovery, disease diagnosis, and personalized medicine.