Generative models have gained significant popularity in recent times. These innovative algorithms, mainly used for unsupervised learning, are proficient in dealing with the underlying distribution of data and generating complex output, such as images, music, and natural language, comparable to the original training data.
Read this chapter to explore three prominent and most widely used types of generative models: Generative Adversarial Networks (GANs), Autoencoders, and Variational Autoencoders (VAEs).
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) were introduced by Ian Goodfellow and his teammates in 2014. GANs, an approach to generative modeling, are based on deep neural network architecture that generates a new complex output that looks like the original training data. GAN framework has two neural networks- ‘Generator’ and ‘Discriminator’.
Working of GANs
Let’s understand the working of GAN model with the help of below given diagram −
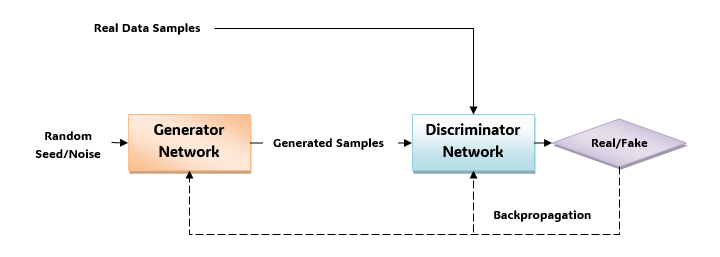
As depicted in the diagram, the GANs has two main components: a generator network and a discriminative network.
The process starts by providing the generator with a random seed/noise vector. Now, the generator uses this input to creates new, synthetic samples. Then, these generated samples along with the real data sample provided to the discriminative network.
The discriminative network then evaluates the realism of these samples, i.e., if the sample if real or fake. Finally, the discriminator provides feedback on the generator”s output by adjusting the generator”s parameters through backpropagation.
The generator and discriminator then continue to learn and adapt to each other, until the generator is producing highly realistic samples that can fool the discriminator.
Application of GANs
Generative Adversarial Networks (GANs) find their applications in various domains. In fact, DALL-E, a specific model developed by OpenAI, combines ideas from GANs and transformers to generate images from textual descriptions.
Some other applications of GANs include the following −
- Image Generation
- Data Augmentation
- Text-to-Image Synthesis
- Video Generation and Prediction
- Anomaly Detection
- Face Aging and Rejuvenation
- Style Transfer and Image Editing
Autoencoders
Another widely used generative model that has revolutionized various domains, from computer vision to natural language processing is autoencoders.
An autoencoder is an designed to learn data encodings in an unsupervised manner. Traditional neural networks, used for supervised learning tasks such as classification and regression, map input data to corresponding output labels. On the other hand, autoencoders learn to reconstruct input data by decoding high-dimensional input data into lower-dimensional representation.
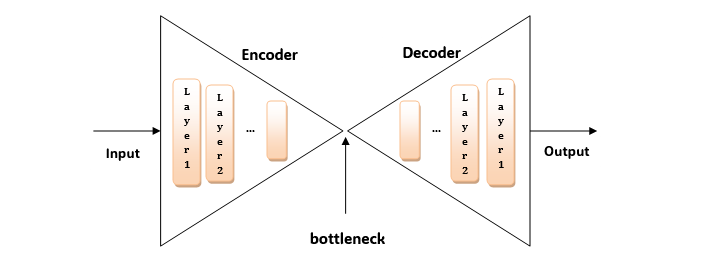
The Architecture of Autoencoders
The architecture of autoencoders consists of three main parts −
- Encoder −It compresses the information into a dense encoding by mapping the input data to a lower-dimensional representation.
- Bottleneck Layer (Latent Space) −In this layer the latent space representation captures the essential features of the input data in a compressed form.
- Decoder −It decompresses the compressed representation back to the original input space by reconstructing it. The main aim of this module is to minimize reconstruction errors.
Application of Autoencoders
Listed below are some of the applications of Autoencoders −
- Image Compression and Reconstruction
- Feature Learning and Representation
- Anomaly Detection
- Dimensionality Reduction
- Natural Language Processing
Variational Autoencoders
Variational autoencoders (VAEs) are a class of generative models that are based on the concept of autoencoders we have studied above.
Traditional autoencoders learn deterministic mappings between input and latent space representations. VAEs, on the other hand, generate parameters for probability distribution in the latent space. This feature enables VAEs to capture the underlying probability distribution of the input data samples.
Architecture and Components of VAEs
Like autoencoders, the architecture of VAEs consists of two main components: an encoder and a decoder. The encoder, in VAEs, rather than using deterministic mappings as in autoencoders, proposes probability modeling into the latent space.
Given below are the key components of VAEs −
- Encoder − It maps the input data samples to the parameters of a probability distribution in the latent space. After mapping the encoder gives mean and variance vectors of each data point.
- Latent Space − This component represents the learned probabilities of the input sample data by the encoder.
- Decoder − It reconstructs the data samples by using the samples from latent space. The aim of the decoder is to match the input data distribution.
Application of Variational Autoencoders (VAEs)
Variational autoencoders (VAEs) find their application across various domains like autoencoders. Some of these are listed below −
- Image Generation
- Data Visualization
- Feature Learning
- Anomaly Detection
- Natural Language Processing
In the subsequent chapters, we will discuss these prominent and most widely used types of generative models in detail.
Conclusion
In this chapter, we presented an overview of the three most widely used generative models namely, Generative Adversarial Networks (GANs), Autoencoders, and Variational Autoencoders (VAEs). Their unique capabilities contribute to the advancements of generative modeling.
GANs, with their adversarial training framework, can generate a new complex output that looks like the original training data. We discussed GANs working using its framework that consists of two neural networks: Generator and Discriminator.
Autoencoders, on the other hand, aim to learn data encodings in an unsupervised manner. They reconstruct input data by decoding high-dimensional input data into lower-dimensional representation.
Variational Autoencoders (VAEs) introduced the probabilistic latent space representations. They bridge the gap between autoencoders and probabilistic modeling by capturing the underlying probability distribution of sample input data.
Whether it’s generating realistic images, learning meaningful representations of data, or exploring the probabilistic latent space representations, GANs, autoencoders, and VAEs shaping the future of AI-driven generative technologies.