Maximum Likelihood Estimation (MLE) is a statistical method providing a principal approach to estimate the parameters of a probability distribution that best describes a given dataset. MLE assumes that the specified distribution generates the data. In simple terms, MLE is a method used to find out the most likely values for the unknown parameters of a model, such as the average or spread of a set of data points. It is something like we guess the missing numbers in a sequence so that it fits the pattern of numbers we already know.
In the field of generative AI, especially in generative models like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), MLE finds extensive applications. For example, while generating images of handwritten digits (0-9), we want our model to generate images that resemble the ones in our dataset (like MNIST). We can achieve this by maximizing the likelihood of observing our training data given the parameters of the model.
maximize Σ log P(x | θ)
We will cover this later in detail when we create our first GAN model using python programming language. Read this chapter to understand the concept of Maximum Likelihood Estimation, its significant role in generative modeling, applications of MLE in generative modeling, and its Python implementation.
Understanding Maximum Likelihood Estimation (MLE)
Maximum Likelihood Estimation (MLE) is a powerful statistical method used to estimate the parameters of probability distributions based on observed data. Let’s understand it in more detail with the help of its mathematical foundations −
Mathematical Foundation of MLE
At the heart of MLE lies the likelihood function: $\mathrm{L(\theta | x)}$. Here, $\mathrm{\theta}$ represents the parameters of the distribution, and x denotes the observed data.
The likelihood function quantifies the probability of observing the data given specific parameter values. Mathematically, it is expressed as the joint probability density function (PDF) or probability mass function (PMF) of the observed data.
$$\mathrm{L(\theta | x) \: = \: f(x | \theta)}$$
To keep the computation simple, we usually work with the log-likelihood function $\mathrm{l(\theta | x)}$, which is the natural logarithm of the likelihood function −
$$\mathrm{l(\theta | x) \: = \: \log L(\theta | x)}$$
Actually, the goal of MLE is to find the parameter values $\mathrm{\hat{\theta}}$ that maximize the likelihood function $\mathrm{L(\theta | x)}$ or equivalently, the log- likelihood function $\mathrm{l(\theta | x)}$ −
$$\mathrm{\hat{\theta} \: = \: argmax_{\theta} L(\theta | x)}$$
Or,
$$\mathrm{\hat{\theta} \: = \: argmax_{\theta} l(\theta | x)}$$
Now, to obtain the maximum likelihood estimates $\mathrm{\hat{\theta}}$, we differentiate the log- likelihood function $\mathrm{l(\theta | x)}$ with respect to the parameters $\mathrm{\theta}$ and set the derivatives equal to zero −
$$\mathrm{\frac{\partial \: l(\theta | x)}{\partial \: \theta} \: = \: 0}$$
Solving the above equation gives the MLE $\mathrm{\hat{\theta}}$.
MLE in Generative Modeling
Generative modeling, as we discussed earlier, involves capturing the underlying distribution of data and generates new data comparable to the original training data. In training generative models, MLE plays a crucial role by estimating the parameters of the underlying probability distribution.
Let’s see how MLE is applied in generative modeling −
Model Selection
We first need to choose a probabilistic model that captures the underlying data distribution. Some of the common models are Gaussian distributions, mixture models, neural networks, etc.
Likelihood Function
Next we need to define the likelihood function. This likelihood function measures the probability of observing the given data. For example, for a given dataset $\mathrm{D \: = \: \lbrace x_{1},x_{2},x_{3},\: \dots \: x_{n} \rbrace}$, the likelihood function $\mathrm{L(\theta | D)}$ depends on the model parameter $\mathrm{\theta}$ and is given by the product of the probabilities of observing each data point −
$$\mathrm{L(\theta | D) \: = \: \prod_{i=1}^N p(x_{i} | \theta)}$$
Maximization
Now we need to maximize the likelihood function with respect to the model parameters $\mathrm{\theta}$. Maximization involves finding the values of $\mathrm{\theta}$ that make the observed data most likely under the model.
Parameter Estimation
Finally, when the likelihood function is maximized, the resulting parameter values are used as the estimates for the parameters of the generative model. These estimated parameters define the learned distribution, which can then be used to generate new data points comparable to the observed data.
Applications of MLE in Generative Modeling
MLE is having wide-range applications across various domains of generative modeling. Given below are some of the significant applications −
- Gaussian Mixture Models (GMMs) − MLE is used to estimate the parameters of Gaussian components in GMMs. These parameters enable the modeling of complex data distributions with multiple modes.
- Variational Autoencoders (VAEs) − In VAEs, MLE is used to learn the parameters of the latent variable distribution. It allows the model to generate new data samples by sampling from this learned distribution.
- Generative Adversarial Networks (GANs) − The GANs do not directly optimize the likelihood function but MLE are used in the training of GANs to guide the learning process and improve sample quality.
Implementing Maximum Likelihood Estimation using Python
We can implement MLE using Python and visualize it using libraries like Matplotlib. Given below is a simple example to perform MLE to estimate the parameters of a Gaussian distribution from a given dataset −
Example
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# Sample dataset (you can replace this with your own data)
data = np.random.normal(loc=2, scale=1, size=2000)
# Maximum Likelihood Estimation for a Gaussian distribution
def maximum_likelihood_estimation(data):
# Calculate the mean and standard deviation of the data
mu = np.mean(data)
sigma = np.std(data)
return mu, sigma
# Perform Maximum Likelihood Estimation
estimated_mu, estimated_sigma = maximum_likelihood_estimation(data)
# Generate x values for plotting
x = np.linspace(min(data), max(data), 1000)
# Plot histogram of the data
plt.figure(figsize=(7.2, 5.5))
plt.hist(data, bins=30, density=True, alpha=0.6, color=''blue'', label=''Data Histogram'')
# Plot the true Gaussian distribution
plt.plot(x, norm.pdf(x, loc=2, scale=1), color=''red'', linestyle=''--'', label=''True Gaussian Distribution'')
# Plot the estimated Gaussian distribution using MLE
plt.plot(x, norm.pdf(x, loc=estimated_mu, scale=estimated_sigma), color=''green'', linestyle=''-'', label=''Estimated Gaussian Distribution (MLE)'')
plt.xlabel(''Value'')
plt.ylabel(''Probability Density'')
plt.title(''Maximum Likelihood Estimation for Gaussian Distribution'')
plt.legend()
plt.grid(True)
plt.show()
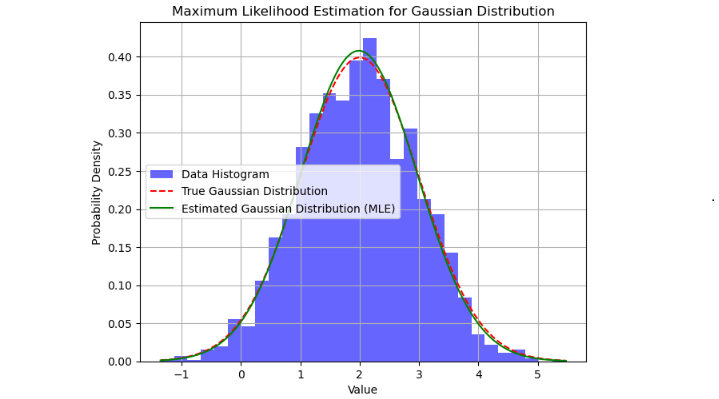
Output
The above code will produce a plot showing the histogram of the data, the true Gaussian distribution, and the estimated Gaussian distribution obtained using Maximum Likelihood Estimation (MLE).
Conclusion
In this chapter, we emphasized MLE”s significance in generative modeling. In generative modeling, MLE serves as the backbone for learning data distributions and generating new samples.
Model Selection, Likelihood Function, Maximization, and Parameter Estimation are the steps with the help of which we can apply MLE in generative modeling.