Human minds inspire Machine Learning (ML) and Deep Learning (DL) technologies, how we learn from our experience to make better choices in the present and future. These technologies are the most dynamic and ever-changing fields of study and while we are already using them in many ways, the possibilities are endless.
These advancements empower machines to learn from past data and predict even from unseen data inputs. To extract meaningful insights from raw data, machines depend upon mathematics, models/algorithms, and data processing methods. There are two ways we can enhance machine efficiency; one is to increase the volume of data, and another is to develop new and more robust algorithms.
Getting fresh data is very easy as quintillions of data are generated daily. But to work with such huge data, we need to either build new or scale up the existing models/algorithms. Mathematics serves as the backbone of these models/algorithms which can be broadly categorized into two groups namely, Discriminative Models and Generative Models.
In this chapter we will be looking at discriminative and generative ML models along with the core differences between them.
What are Discriminative Models?
Discriminative models are ML models and, as the name suggests, concentrate on modeling the decision boundary between several classes of data using probability estimates and maximum likelihood. These types of models, mainly used for supervised learning, are also known as conditional models.
Discriminative models are not much affected by the outliers. Although this makes them a better choice than generative models, it also leads to misclassification problem which can be a big drawback.
From a mathematical perspective, the process of training a classifier involves estimating either,
- A function represented as f : X → Y, or
- The probability P(Y│X).
However, discriminative classifiers −
- Assume a particular functional form of probability P(Y|X), and
- Directly estimate the parameters of probability P(Y|X) from the training dataset.
Popular Discriminative Models
Discussed below are some examples of widely used discriminative models −
Logistic Regression
Logistic Regression is a statistical technique used for binary classification tasks. It models the relationship between the dependent variable and one or more independent variables using the logistic function. It produces an output between 0 and 1.
Logistic regression can be used for various classifications of problems like cancer detection, diabetes prediction, spam detection, etc.
Support Vector Machines
A support vector machine (SVM) is a powerful yet flexible supervised ML algorithm with applications in regression as well as classification scenarios. Support vectors divide an n-dimensional data space into numerous classes in a hyperplane using decision boundaries.
K-nearest Neighbor (KNN)
KNN is a supervised ML algorithm that uses feature similarity to predict new data points value. The values assigned to new data points depend on how closely they match the points in the training set.
Decision trees, neural nets, conditional random field (CRF), random forest are few other examples of the commonly used discriminative models.
What are Generative Models?
Generative models are ML models and, as the name suggests, aim to capture the underlying distribution of data, and generate new data comparable to the original training data. These types of models, mainly used for unsupervised learning, are categorized as a class of statistical models capable of generating new data instances.
The only drawback of generative models, when compared to discriminative models, is that they are prone to outliers.
As discussed above, from a mathematical perspective, the process of training a classifier involves estimating either,
- A function represented as f : X → Y, or
- The probability P(Y│X).
However, generative classifiers −
- Assume a particular functional form for the probabilities such as P(Y), P(X|Y)
- Directly estimate the parameters of probability such as P(X│Y), P(Y) from the training dataset.
- Calculates the posterior probability P(Y|X) using the Bayes’ Theorem.
Popular Generative Models
Highlighted below are some examples of widely used generative models −
Bayesian Network
A Bayesian Network, also known as Bayes’ network, is a probabilistic graphical model that represents relationships between variables using a directed acyclic graph (DAG). It has many applications in various fields such as healthcare, finance, and natural language processing for tasks like decision-making, risk assessment, and prediction.
Generative Adversarial Network (GAN)
These are based on deep neural network architecture consisting of two main components namely a generator and a discriminator. The generator trains and creates new data instances and the discriminator evaluates these generated data into real or fake instances.
Variational Autoencoders (VAEs)
These models are a type of autoencoder, trained to learn a probabilistic latent representation of the input data. It learns to generate new samples like the input data by sampling from a learned probability distribution. VAEs are useful for tasks like generating images from text descriptions, as seen in DALL-E-3, or crafting human-like text responses like ChatGPT.
Autoregressive model, Naïve Bayes, Markov random field, Hidden Markov model (HMM), Latent Dirichlet Allocation (LDA) are few other examples of the commonly used generative models.
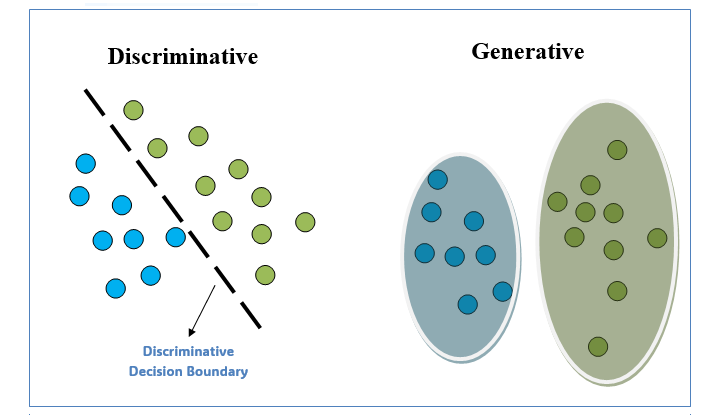
Difference Between Discriminative and Generative Models
Data scientists and machine learning experts need to understand the differences between these two types of models to choose the most suitable one for a particular task.
The table below depicts the core differences between discriminative and generative models −
| Characteristic | Discriminative Models | Generative Models |
|---|---|---|
| Objective | Focus on learning the boundary between different classes directly from the data. Their primary objective is to classify input data accurately based on the learned decision boundary. | Aim to understand the underlying data distribution and generate new data points that resemble the training data. They focus on modeling the process of data generation, allowing them to create synthetic data instances. |
| Probability Distribution | Estimates the parameters of probability P(Y|X) from the training dataset. | Calculates the posterior probability P(Y|X) using the Bayes’ Theorem. |
| Handling Outliers | Relatively robust to outliers | Prone to outliers |
| Property | They do not possess generative properties. | They possess discriminative properties. |
| Applications | Commonly used in classification tasks, such as image recognition and sentiment analysis. | Commonly used in tasks like data generation, anomaly detection, and data augmentation, beyond traditional classification tasks. |
| Examples | Logistic regression, Support vector machines, Decision trees, neural nets etc. | Variational Autoencoders (VAEs), Generative adversarial network (GAN), Naïve Bayes etc. |
Conclusion
Discriminative models create boundaries between classes which make them ideal for classification tasks. In contrast, generative models understand the underlying data distribution and generate new samples which make them suitable for tasks such as data generation and anomaly detection.
We also explained some core differences between discriminative and generative models. These differences empower data scientists and machine learning experts to choose the most suitable approach for specific tasks and enhance the efficacy of machine learning systems.