Voice Recognition
Voice recognition biometric modality is a combination of both physiological and behavioral modalities. Voice recognition is nothing but sound recognition. It relies on features influenced by −
-
Physiological Component − Physical shape, size, and health of a person’s vocal cord, and lips, teeth, tongue, and mouth cavity.
-
Behavioral Component − Emotional status of the person while speaking, accents, tone, pitch, pace of talking, mumbling, etc.
Voice Recognition System
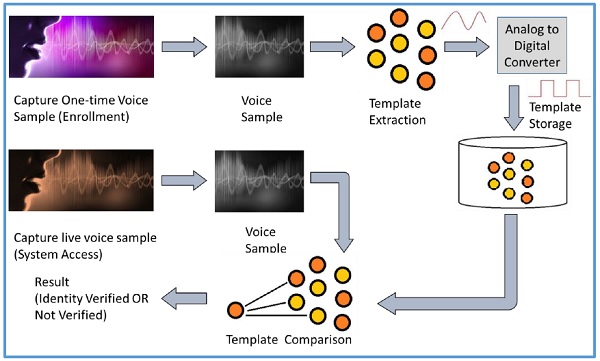
Voice Recognition is also called Speaker Recognition. At the time of enrollment, the user needs to speak a word or phrase into a microphone. This is necessary to acquire speech sample of a candidate.
The electrical signal from the microphone is converted into digital signal by an Analog to Digital (ADC) converter. It is recorded into the computer memory as a digitized sample. The computer then compares and attempts to match the input voice of candidate with the stored digitized voice sample and identifies the candidate.
Voice Recognition Modalities
There are two variants of voice recognition − speaker dependent and speaker independent.
Speaker dependent voice recognition relies on the knowledge of candidate”s particular voice characteristics. This system learns those characteristics through voice training (or enrollment).
-
The system needs to be trained on the users to accustom it to a particular accent and tone before employing to recognize what was said.
-
It is a good option if there is only one user going to use the system.
Speaker independent systems are able to recognize the speech from different users by restricting the contexts of the speech such as words and phrases. These systems are used for automated telephone interfaces.
-
They do not require training the system on each individual user.
-
They are a good choice to be used by different individuals where it is not required to recognize each candidate’s speech characteristics.
Difference between Voice and Speech Recognition
Speaker recognition and Speech recognition are mistakenly taken as same; but they are different technologies. Let us see, how −
| Speaker Recognition (Voice Recognition) | Speech Recognition |
|---|---|
| The objective of voice recognition is to recognize WHO is speaking. | The speech recognition aims at understanding and comprehending WHAT was spoken. |
| It is used to identify a person by analyzing its tone, voice pitch, and accent. | It is used in hand-free computing, map, or menu navigation. |
Merits of Voice Recognition
- It is easy to implement.
Demerits of Voice Recognition
- It is susceptible to quality of microphone and noise.
-
The inability to control the factors affecting the input system can significantly decrease performance.
-
Some speaker verification systems are also susceptible to spoofing attacks through recorded voice.
Applications of Voice Recognition
- Performing telephone and internet transactions.
-
Working with Interactive Voice Response (IRV)-based banking and health systems.
- Applying audio signatures for digital documents.
- In entertainment and emergency services.
- In online education systems.
Learning working make money